


日本語音声基盤モデル「いざなみ」「くしなだ」を公開
少量の日本語音声データで高性能な音声AIを構築可能に
ポイント
・ 豊かな感情表現を含む6万時間の日本語音声データから2種類の日本語音声基盤モデルを構築
・ モデルの改良が容易な「いざなみ」と感情認識や音声認識の能力がより高い「くしなだ」を一般公開
・ 少量データを活用した音声AIの構築・普及に貢献

概 要
国立研究開発法人 産業技術総合研究所(以下「産総研」という)人工知能研究センター 深山覚 研究チーム長、緒方淳 客員研究員は、高性能な音声AI構築に利用可能な2種類の日本語音声基盤モデル「いざなみ」「くしなだ」を公開しました。
音声基盤モデルとは、音声データを処理・解析するための汎用的なAIモデルで、音声認識や音声感情認識などに応用が進んでいます。音声基盤モデルの構築には、対象とする言語やそれが使われるシーンを想定した音声データが少なくとも数千時間必要です。しかし読み上げ調のものに比べ会話などの音声データは少なく、感情豊かな表現を含む会話の音声では音声AIの性能が不十分でした。
今回、6万時間という過去最大規模の日本語音声データを用い「くしなだ」「いざなみ」という2種類の日本語音声基盤モデルを構築・公開しました。モデルの名前は今後多様な音声AIの生みの親やサポート役となることを願い、日本の神話からとっています。
「いざなみ」は利用者のデータを用いて容易に改良でき、「くしなだ」は日本語の音声感情認識と音声認識に高い性能を発揮します。これらにより、高齢者の音声や感情豊かな表現を含む会話など、教師データが少量しかない場合でも高性能な音声AIを構築できます。今後は日本語方言の音声認識性能の向上にも取り組みます。地域や世代の違いにより音声AIの性能が低下する問題の改善や、地方議会での議事録作成など多くの場面で活用が期待されます。
なお、本モデルはAIモデル公開プラットフォームHugging Face(https://huggingface.co/imprt)からダウンロード可能です。
下線部は【用語解説】参照
開発の社会的背景
音声を文字起こしする音声認識、話者の感情分析などの音声AIは、スマートスピーカーや会議の文字起こしなどに使用されています。音声データは話者や感情、音響環境などの違いによって特徴が変化する複雑なデータです。アナウンサーが静穏な環境で読み上げる場合、容易に教師データを入手できるため、教師あり学習で高性能の音声AIが構築できます。しかし感情表現豊かな会話音声や、多様な世代の音声は教師データの量が十分でなく、感情認識や音声認識の性能が不十分でした。そのような中、音声基盤モデルは音声データを解析できる汎用的なAIモデルとして注目されています。音声基盤モデルは教師データなしの自己教師あり学習で構築できます。音声基盤モデルを通じて得られる汎用的な音声の特徴表現を用いることで、少量の音声データと教師データで高性能の音声AIが構築でき、そのように構築された音声AIの介護施設などの場所での活用が期待されます。
研究の経緯
産総研では、これまで少量の音声データから高性能な音声AIを構築するための音声基盤モデルの研究開発を進めてきました。約5千時間の日本語音声データを用いて構築した日本語音声基盤モデルにより、日本語の音声感情認識の性能を向上できることを確認しました[1]。日本語音声データには、ニュース番組やドラマ等の喜怒哀楽の自然感情音声、演技感情音声が含まれます。今回音声データを12倍の約6万時間収集し、日本語音声基盤モデル「いざなみ」と「くしなだ」の開発に取り組みました。
「いざなみ」の開発は、NEDO(国立研究開発法人 新エネルギー・産業技術総合開発機構)の委託事業「人と共に進化する次世代人工知能に関する技術開発事業(課題番号:P20006)」による支援を、「くしなだ」の開発は産総研政策予算プロジェクト「フィジカル領域の生成AI基盤モデルに関する研究開発」による支援を受けています。また、本成果は産総研ABCI2.0の一定部分(Aノードと呼ばれる高性能な計算ノード)を一定期間占有利用する機会を提供する「大規模生成AI研究開発支援プログラム」の支援を受けています。
研究の内容
過去最大規模(約6万時間)の音声データを用いて日本語音声基盤モデル「いざなみ」と「くしなだ」を構築・公開しました。「いざなみ」や「くしなだ」は日本語の音声認識や音声合成、音声感情認識などの用途に応用でき、教師データが少量しかない場合でも高性能な音声AIが構築できます。図1に日本語音声基盤モデルの構築と使い方についての説明を示します。
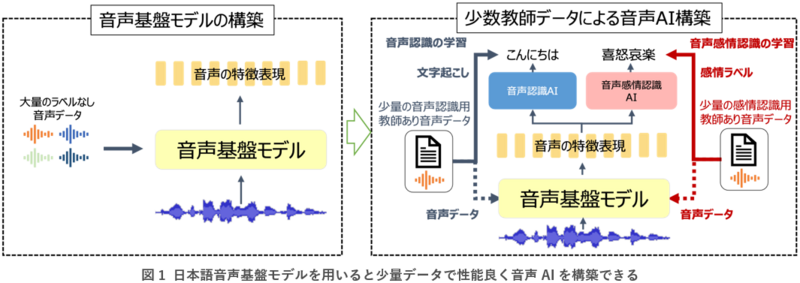
これまでの音声基盤モデルは主に英語音声で学習されており、多言語音声で学習されている場合でも日本語音声は少量でした。これらの音声基盤モデルでは、日本語音声の特性や感情表現の処理・解析に適しておらず、音声感情認識の性能も限定的でした。日本語音声で学習されている日本語音声基盤モデルとしては、これまでに2万時間の日本語音声データを用いたモデルが公開されています。
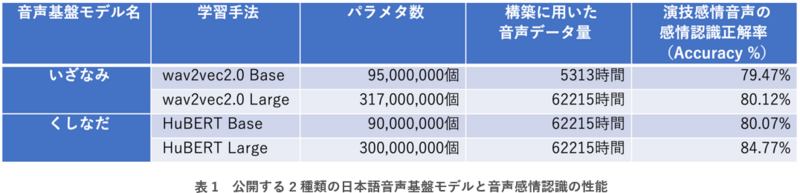
今回、日本語音声基盤モデルの学習データとしてテレビ放送音声に含まれるあらゆる音声に注目しました。ニュース番組やドラマ等のテレビ放送音声には、喜怒哀楽の感情表現豊かな音声や多様な世代の音声が含まれています。従来の日本語音声基盤モデルの構築では、テレビ放送音声のうち文字起こしがされた部分のみが使われていました。今回、日本語音声データとして過去最大規模の約6万時間を収集し、強い感情表現のような文字起こしが難しい音声も含めた日本語音声を学習に使って日本語音声基盤モデルを構築しました。構築手法としては「いざなみ」にwav2vec2.0を、「くしなだ」にはHuBERTを用いました。「いざなみ」は音声AIを活用する現場のデータによって改良が容易なモデルです。他方で「くしなだ」は日本語の音声感情認識と音声認識に高い性能を発揮します。性能評価の結果、日本語の演技感情音声の音声感情認識(喜び/怒り/悲しみ/平常の識別)において「いざなみ」で80.12%、「くしなだ」で84.77%の正解率を達成しました(表1)。この性能は日本語音声基盤モデルを用いない場合の正解率70.65%と比べ10ポイント以上改善しています。また他の日本語基盤モデルとの性能比較も行い、「いざなみ」と「くしなだ」の性能が優っていることを確認しました。
学習手法、大きいほどモデルが大規模であることを示すパラメタ数、および学習に用いた音声データ量が異なる「いざなみ」と「くしなだ」の2種類合計4つの日本語音声基盤モデルを公開します。公開する日本語音声基盤モデルの種類と、音声感情認識の性能を表1に示します。
今後の予定
音声AIの地域や世代による性能差の改善のために、日本語音声基盤モデルを使って日本語方言の音声認識の性能向上に取り組んでいます[2]。「くしなだ」を用いて日本語方言による会話音声の音声認識を行ったところ、音声認識の性能指標である文字誤り率が32.7%でした。この性能は現在公開されている他の音声基盤モデルを用いた場合と同程度であることを確認しており、現時点の最高性能といえます。しかし標準語の日本語音声では、10%以下の文字誤り率の音声認識があることを踏まえると、まだまだ良い性能とはいえません。「くしなだ」を標準語の音声認識に用いると文字誤り率は10.9%であり、方言の会話によって性能が22ポイントほど悪化していました。今後新たな方言音声データセットの構築などを行い、地域や世代の違いにより音声AIの性能が低下する問題の改善に取り組みます。また「いざなみ」と「くしなだ」を企業・大学等と連携して活用し、少量データを活用した音声AIの構築・普及に貢献していきます。
参考文献
[1] 掲載誌:日本音響学会第150回(2023年秋季)講演論文集
論文タイトル:日本語音声感情認識のための自己教師あり学習モデルの検討
著者:瀧澤大吾、緒方淳、近井学、佐藤洋
[2] 掲載誌:日本音響学会第153回(2025年春季)講演論文集
論文タイトル:大規模自己教師あり学習モデルによる日本語方言の音声認識
著者:瀧澤大吾、中村友彦、須田仁志、深山覚
入手先
日本語音声基盤モデル「いざなみ」と「くしなだ」はAIモデル公開プラットフォームHugging Face(https://huggingface.co/imprt)からダウンロード可能です。
用語解説
音声AI
人間の発話や対話を分析・生成する人工知能技術。音声をテキストに書き起こす音声認識、音声から感情を認識する音声感情認識、テキストから音声を生成する音声合成などがあります。
音声感情認識
音声から話者の感情を分析・認識する技術。音声の音響的特徴を解析し、話者がどのような感情を抱いているかを推定します。
教師データ
入力データに対応する正解を示すデータのこと。音声感情認識では、喜び/怒り/悲しみ/平常のカテゴリ等を正解として、入力する音声と対にして用います。
教師あり学習
入力データとそれに対応する正解(教師データ)を対にして学習を行う機械学習手法。未知の入力に対して正解を出力できるようにモデルの学習を行います。
自己教師あり学習
学習データの一部を隠すなどして擬似的な教師データを作ることで、教師データなしでモデルの学習を行う機械学習手法。大量の教師データを用意する手間を省いて、高性能なモデルを構築できます。
自然感情音声・演技感情音声
自然感情音声は、日常会話や自然な状況で感情が表現された音声をいいます。演技感情音声は、声優や俳優が演技を通じて感情を表現する音声です。
wav2vec2.0
米Meta社が開発した機械学習手法で、音声の符号化と予測を同時に行う自己教師あり学習を行います。
HuBERT
米Meta社が開発した機械学習手法で、多段階の学習を通じて音声認識等に有用な音声の特徴表現の符号化と予測を行う自己教師あり学習を行います。
プレスリリースURL
https://www.aist.go.jp/aist_j/press_release/pr2025/pr20250310/pr20250310.html
.jpg)
-1.jpg)
_クレジット追加.jpg)
.jpg)




