


量子インスパイアード技術を用いた大量データのクラスタリング手法の開発
多様な分野における画像を含む時系列データの分析に利用
2024年1月11日
早稲田大学
東北大学
愛知工業大学
量子インスパイアード技術を用いた大量データのクラスタリング手法の開発
多様な分野における画像を含む時系列データの分析に利用
詳細は、早稲田大学Webサイトをご覧ください。
発表のポイント
●科学、工学、環境、農業、生命科学、経済学をはじめ多くの分野で、時間とともに変化するデータ(時系列データ)を大量に収集し、類似度に応じて適切にグループ分け(クラスタリング)し、特徴的な挙動を解析することが重要となっています。
● 本研究では、時系列データのクラスタリングを組合せ最適化問題として捉え、この問題に特化した量子インスパイアード技術を適用することで、大量なデータのクラスタリングを高速に行うことに成功しました。
● 外れ値を考慮しつつ所望のクラスタリングを行う新たな方法を提案し、大きなノイズを含む画像データにおいて高い精度のクラスタリングを行うことができることを実証しました。
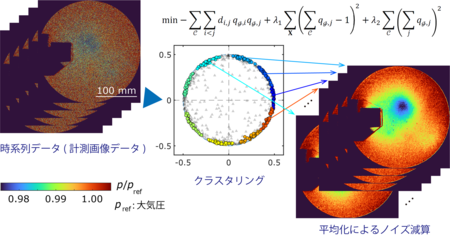
図1: 本研究による高精度クラスタリング結果
早稲田大学理工学術院教授 松田佑(まつだゆう)、同大学院生 井上智輝(いのうえともき)、窪田航陽(くぼたこうよう)、東北大学流体科学研究所教授 永井大樹(ながいひろき)、同助教 伊神翼(いかみつばさ)、愛知工業大学工学部教授 江上泰広(えがみやすひろ)らの研究グループ(以下、「本研究グループ」とする)は、大きなサイズで大量の時系列データ*1のクラスタリング*2を組合せ最適化問題*3として捉え、これに特化した計算技術を応用して高速な計算を可能としました。また、どのクラスタにも相応しくない外れ値を、クラスタに含まないようなアルゴリズム構築を行いました。これにより、多分野での画像を含む時系列データの解析に本手法が貢献できると期待されます。
このたびの成果は、英国の科学雑誌Natureが運営するオープンアクセスジャーナル『Communications Engineering』に、“Clustering Method for Time-Series Images Using Quantum-Inspired Digital Annealer Technology”として、2024年1月10日(現地時間)に掲載されました。
(1) 今回の研究の背景・課題
科学、工学、環境、農業、生命科学、経済学をはじめとして非常に多くの分野において、時系列データが収集されています。複雑な挙動を示す多くのデータを適切にクラスタリングし、特徴的な挙動を抽出し解析することが、複雑な現象への理解を深めるための非常に重要なプロセスと認識されています。
このような時系列データのクラスタリングを行う方法は「時系列クラスタリング」と総称され非常に盛んに研究が行われています。近年では、データストレージの大容量化やセンサ性能の向上が劇的に進み、また画像データを扱うことも増えており、大きなサイズのデータが大量に得られるようになりました。そのため、このようなデータの巨大な集合を高速にクラスタリングすることが必要になっています。
(2)今回の研究で新たに実現したこと
一般に時系列クラスタリングでは時系列データの集合の中から、互いのデータの類似度を計算し、その類似度に応じてデータをクラスタリングします。すなわち、類似度の高い似通ったデータをひとまとまりのクラスタとして、類似度が低く似ていないデータと区別していきます。
データサイズが大きくなり、データ数も大量になると、このクラスタリングの計算に時間がかかります。クラスタリングは組合せ最適化問題のひとつと考えることができるため、組合せ最適化問題に特化した量子コンピュータなどで注目度の高い新しい計算技術が活用でき、高速な計算が可能です。一方で、クラスタリングを行う際には、しばしばどのクラスタにも相応しくないデータ(外れ値)も出てきます。このような外れ値をクラスタに含まないようなアルゴリズムを開発しました。
(3)新しく開発した手法
本研究グループは、
① 各クラスタに入るデータ間の類似度の和が大きくなる
② 1つのデータは最大1つのクラスタに入る
③ 各クラスタに入るデータ数とその分散を調整する
という3つの制約を課すクラスタリング方法(以下、「本手法」とする)を開発しました。
条件①は、互いに似通ったデータを同じクラスタに入れるための条件です。条件②は1つのデータが複数のクラスタに入っていると解析において不都合となる場合が多いので、これを避けるための条件になっています。条件③は、クラスタに含まれるデータ数と分散を調整します。これによって各クラスタの大きさを調整します。例えばクラスタに含まれるデータ数を多く設定すれば、外れ値をクラスタに含みやすくなります。逆にクラスタに含まれるデータ数を少なくすれば、外れ値をクラスタに含まなくなります。なお、これらの3つの条件の重みを変えることで、例えば同頻度で各クラスタに該当する現象が生じていると予想される場合に、各クラスタに入るデータ数を揃えることもできます。本研究ではこの例として、周期的な時系列データに対して本手法を適用しています。
本手法は、条件に合うようなデータの組合せを考える組合せ最適化問題となっています。本研究グループは、この組合せ最適化問題を解くために、Fujitsu Computing as a Serviceの構成技術のひとつで組合せ最適化問題の計算に特化した新しい計算技術であるComputing as a Service Digital Annealer (以下、「富士通デジタルアニーラ」*4とする)を利用しました。
(4)研究の波及効果や社会的影響
時系列データは非常に多くの分野で用いられています。今回は流体計測画像を例としてクラスタリング例を実証しました。このデータは非常に大きなノイズを含んでいますが、本手法で上手くクラスタリングできることを示しました。このようなケースは流体計測に限らず他の分野でも多くあると考えられます。今回発表した論文においては、本手法は基礎的な内容となっていますが、その分、気象、生命科学、経済をはじめとして応用分野が広いと考えています。また近年では、新しいコンピューティング技術の開発が活発に行われております。これらのコンピューティング技術を広い分野の研究に活用するという視点からもインパクトが大きいといえます。
(5)研究者のコメント
今後、計測によって得られる時系列データは増加の一途をたどると考えられ、これらを上手く解析することが重要となります。時系列クラスタリングは富士通デジタルアニーラのように組合せ最適化問題に特化した計算技術を有効に利用できる分野であり、各専門分野での解析に活用いただければ幸甚です。
(6)用語解説
※1 時系列データ
時間と共に変化する量についてのデータ。例えば、気温の時間変化、株価や為替相場など。
※2 クラスタリング
データを類似度に応じてグループ分けすること。教師なしの機械学習のひとつ。教師あり学習である「分類」とは異なる。作られたグループはクラスタと呼ばれる。また類似度とは2つのデータがお互いにどれだけ似ているのかを示す指標。
※3 組合せ最適化問題
考えられる組合せの中から、与えられた条件を満たす最適な組合せを選ぶ問題。巡回セールスマン問題やナップサック問題などがよく知られている。
※4 富士通デジタルアニーラ
富士通株式会社がサービス提供している、量子現象に着想を得たコンピューティング技術で、組合せ最適化問題を高速に解く技術。
https://www.fujitsu.com/jp/digitalannealer/index.html
(7)論文情報
雑誌名:Communications Engineering
論文名:Clustering Method for Time-Series Images Using Quantum-Inspired Digital Annealer Technology
執筆者名(所属機関名):井上智輝(早稲田大)、窪田航陽(早稲田大)、伊神翼(東北大)、江上泰広(愛知工業大)、永井大樹(東北大)、柏川貴弘(富士通)、木村浩一(富士通)、松田佑(早稲田大)
掲載日時(現地時間):2024年1年10日(水)
掲載URL:https://doi.org/10.1038/s44172-023-00158-0
DOI:10.1038/s44172-023-00158-0
.jpg)
-1.jpg)
_クレジット追加.jpg)
.jpg)




